
2」三维点云语义分割和实例分割综述
过犹不及,止于至善
Your follow means everything to me, hahaha, thanks!
目录
三维数据的表示方法👉
论文分析👉
三维数据的表示方法
三维数据有四种表示方法,分别是point cloud(点云),Mesh(网格),Voxel(体素)以及Multi-View(多角度图片),由此衍生出四种不同的三维数据的语义和实例分割的方法。近两年来针对point cloud的算法越来越多,也逐渐有了竞争能力。本篇博客只分析基于point cloud的算法。
数据集有ShapeNet,S3DIS,ModelNet40等
论文分析
Pointnet👉
Pointnet++👉
SPLATNet
SGPN👉
RSnet👉
SPGraph👉
PointCNN👉
PointSIFT👉
3P-RNN
ASIS👉
Pointnet
为什么是开山之作:之前为了能把处理二维数据好的算法套用在三维中,所以都把数据处理成能用二维卷积去做的形式,而pointnet直接把坐标当作三维数据去做,抛弃了处理二维数据的经验,另辟蹊径,所以说是开山之作。
模型需对点的顺序和刚体变换都保持不变性,采用了对称函数(解决旋转和变换)和maxpooling(解决无序性);其中对称函数是mlp以及一个3✖️3的坐标变换矩阵,和64✖️64的特征变换矩阵(均为T-Net产生的)
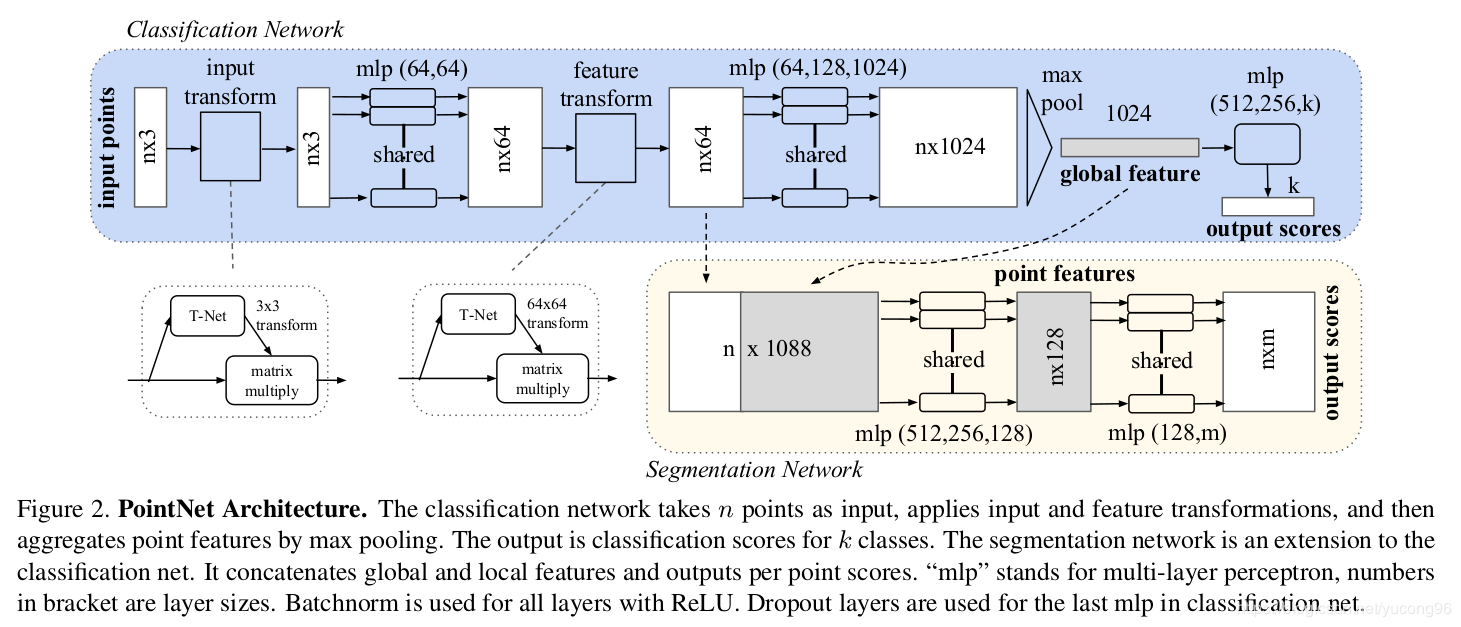
concate了一下低维和高维的特征,美其名曰局部和总体特征的结合,喵喵喵???
论文中有鲁棒性测试和时间空间复杂度分析,估计等这一领域的accuracy提高了就会纠结这些个指标了,害…
Pointnet++
解决Pointnet的问题:1、PointNet不捕获由度量空间点引起的局部结构,限制了它识别细粒度图案和泛化到复杂场景的能力。 利用度量空间距离,Pointnet++能够通过增加上下文尺度来学习局部特征。2、点集通常采用不同的密度进行采样,这导致在统一密度下训练的网络的性能大大降低。Pointnet++新的集合学习层来自适应地结合多个尺度的特征。
1、如何对点云进行局部划分
对数据集进行划分,提取局部特征,然后不断抽象,提取更高维的特征,是PointNet++的基本思路,那么首先的问题是如何定义局部,PointNet++给出的解决思路是使用点球模型,从全部数据集中选出若干质心点,然后选取半径,完成覆盖整个数据集的任务。在质心点的选取上,采用的是FPS算法,即随机选取一个点,然后选择离这个点最远的点加入到结果集中,迭代这个过程,直到结果集中点的数量达到某个给定值。(FPS算法在之后的很多其他论文工作中都被用到)在PointNet++中,很常见的一个词是metric,即度量,PointNet++中的很多东西都是依赖度量的,而在PointNet中,其实对于度量并不是很强调,或者细究的话都有可能不需要是度量空间(这个度量指的是什么呢?)。在读到中心点的集合后,第二个问题是如何选择半径,其实半径的选取是个很麻烦的事,在点云数据集中,有些地方比较稠密,有些地方比较稀疏,稠密的地方必然半径要小,而稀疏的地方必然半径要大,不然可能都提取不出什么特征,此时引出第二个问题——密度适应,若半径确定,即局部大小确定,此时训练的模板大小也就确定了。
2、如何对点云进行局部特征提取
每个图层都有三个子阶段:采样,分组和PointNeting。在第一阶段,选择质心,在第二阶段,把他们周围的邻近点(在给定的半径内)创建多个子点云。然后他们将它们给到一个PointNet网络,并获得这些子点云的更高维表示。然后,他们重复这个过程。
(这两个问题是关联的)
3、如何进行密度适应?
论文中提到的处理密度适应的方法有两种
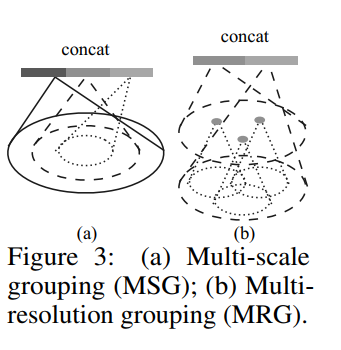
方法一为MSG,即把每种半径下的局部特征都提取出来,然后组合到一起.作者在如何组合的问题上提到了一种random dropping out input points的方法,存在两个参数p和q,每个点以q的概率进行丢弃,而q为在[0,p]之间均匀采样,这样做,可以让整体数据集体现出不同的稠密性和均匀性。MSG有一个巨大的问题是运算的问题,然后作者提出we can avoid the feature extraction in large scale neighborhoods at lowest levels,因为在低层级处理大规模数据,可能模板处理能力不够,感受野有些过大,基于此,作者提出了MRG。
方法二MRG有两部分向量构成,分别为上一层即Li-1层的向量和直接从raw point上提取的特征构成,当点比较稀疏时,给从raw point提取的特征基于较高的权值,而若点比较稠密,则给Li-1层提取的向量给予较高的权值,因为此时raw point的抽象程度可能不够,而从Li-1层的向量也由底层抽取而得,代表着更大的感受野。当局部区域的密度较低时,第一个矢量可能不如第二个矢量可靠,因为在计算第一个矢量中的子区域包含更稀疏的点并且更多地受到抽样不足的影响。 在这种情况下,第二个向量应该加权得更高。 当局部区域的密度很高时,第一个矢量提供更精细的细节信息,因为它具有以较低分辨率递归地检查较高分辨率的能力。
4、整体分析
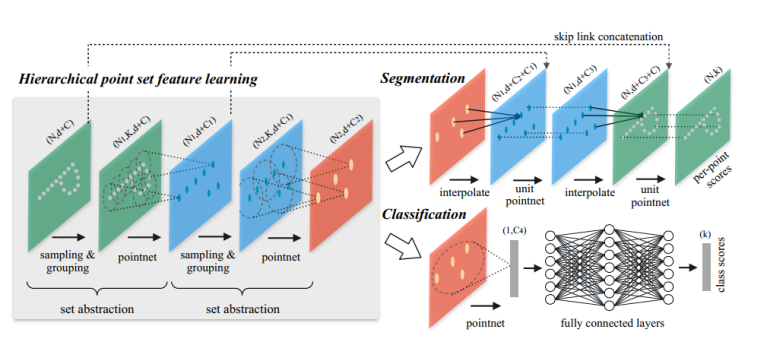
在整体网络结构中,首先进行set abstraction,这一部分主要即对点云中的点进行局部划分,提取整体特征,如图可见,在set abstraction中,主要有Sampling layer、Grouping layer、以及PointNet layer三层构成,sampling layer即完成提取中心点工作,采用fps算法,而在grouping中,即完成group操作,采用mrg或msg方法,最后对于提取出得点,使用pointnet进行特征提取。在msg中,第一层set abstraction取中心点512个,半径分别为0.1、0.2、0.4,每个圈内的最大点数为16,32,128。在classification的处理上,与pointnet相似。
SGPN
实例分割的论文
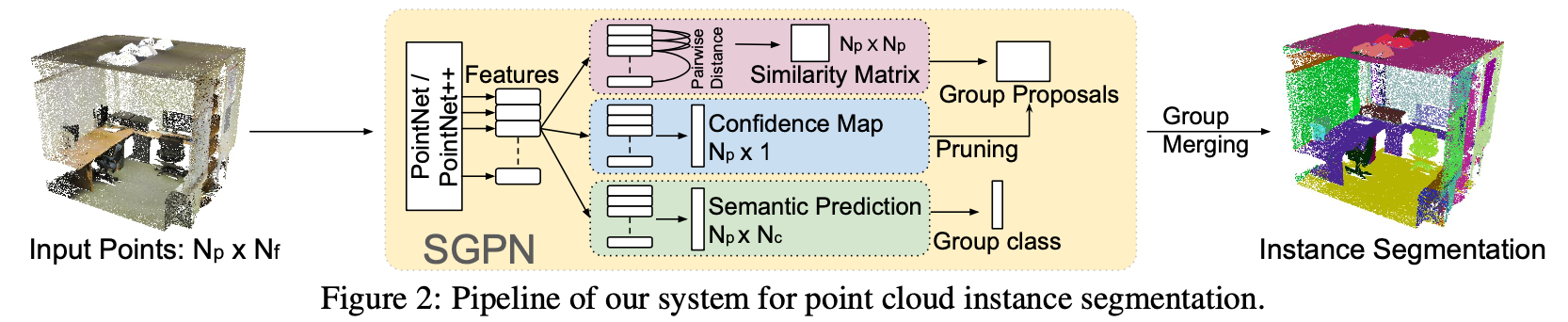
论文里,对FSIM、FCF和FSEM说的有些迷糊;看了一下源码,
` F = pointnet.get_model(point_cloud, is_training, bn=True, bn_decay=bn_decay)
Fsem = tf_util.conv2d(F, 128, [1, 1], padding=’VALID’, stride=[1, 1], bn=False, is_training=is_training, scope=’Fsem’)
Fsim = tf_util.conv2d(F, 128, [1, 1], padding=’VALID’, stride=[1, 1], bn=False, is_training=is_training, scope=’Fsim’)
Fconf = tf_util.conv2d(F, 128, [1, 1], padding=’VALID’, stride=[1, 1], bn=False, is_training=is_training, scope=’Fsconf’)`
可以看出是在pointnet/pointnet++提取了特征F之后,每个加了一个卷积层,生成了FSIM、FCF和FSEM;然后再进行不同的处理;
说一下Similarity Martix,这个可以和图的构建进行比较,生成的Np*Np的矩阵,可以看作节点与节点之间的边的权重;另外许多表述也都是图算法中的表述,做这方面有必要也了解图卷积之类的
另外就是Loss😉的设置了,用了hinge loss,我感觉这篇论文和算法就很…emmm…随意,但是它work了,我真的惊呆了,🤦♂️
Group Proposal Merging😉
直接通过相似矩阵生成的聚类结果会存在较多的噪声和重叠。本文通过去除一些置信度较低的聚类结果,并进一步使用极大值抑制等方法最终得到一个噪声较低和没有重叠的聚类结果。 当聚类完成后,每一个点都会属于某一个实例。但是在两个实例的相邻区域,点则可能属于两个实例;本文的方案就是将该点随机设置为某一个实例。
RSNet
网络整体结构:
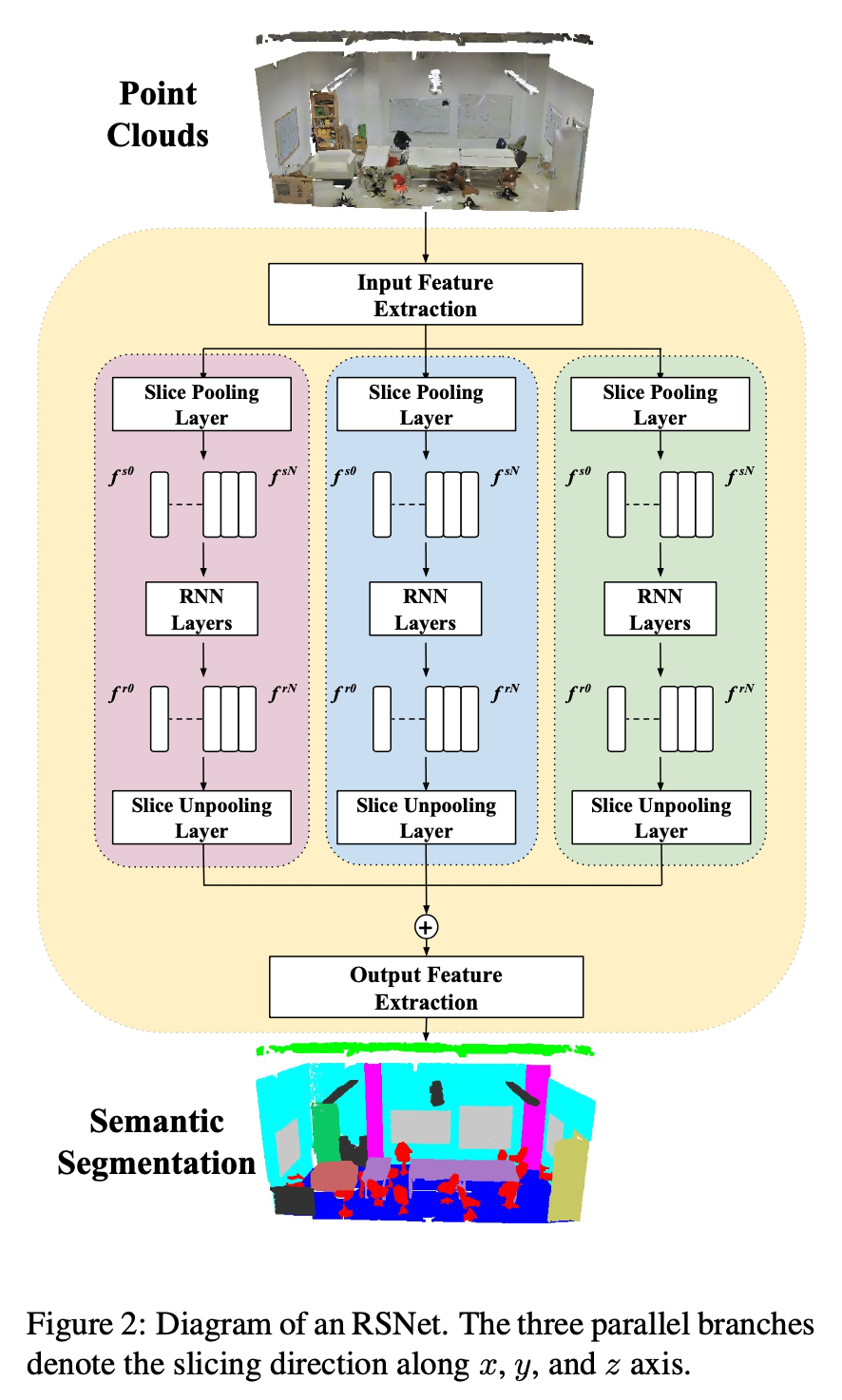
分析:
1、 Input Feature Extraction 和 Output Feature Extraction都是1✖️1的卷积层; 但我觉得这两个地方太过于简单了,尤其是output feature extration。
2、3个分支是分别对x,y,z三个方向进行切割并处理的;
3、slice pooling operation
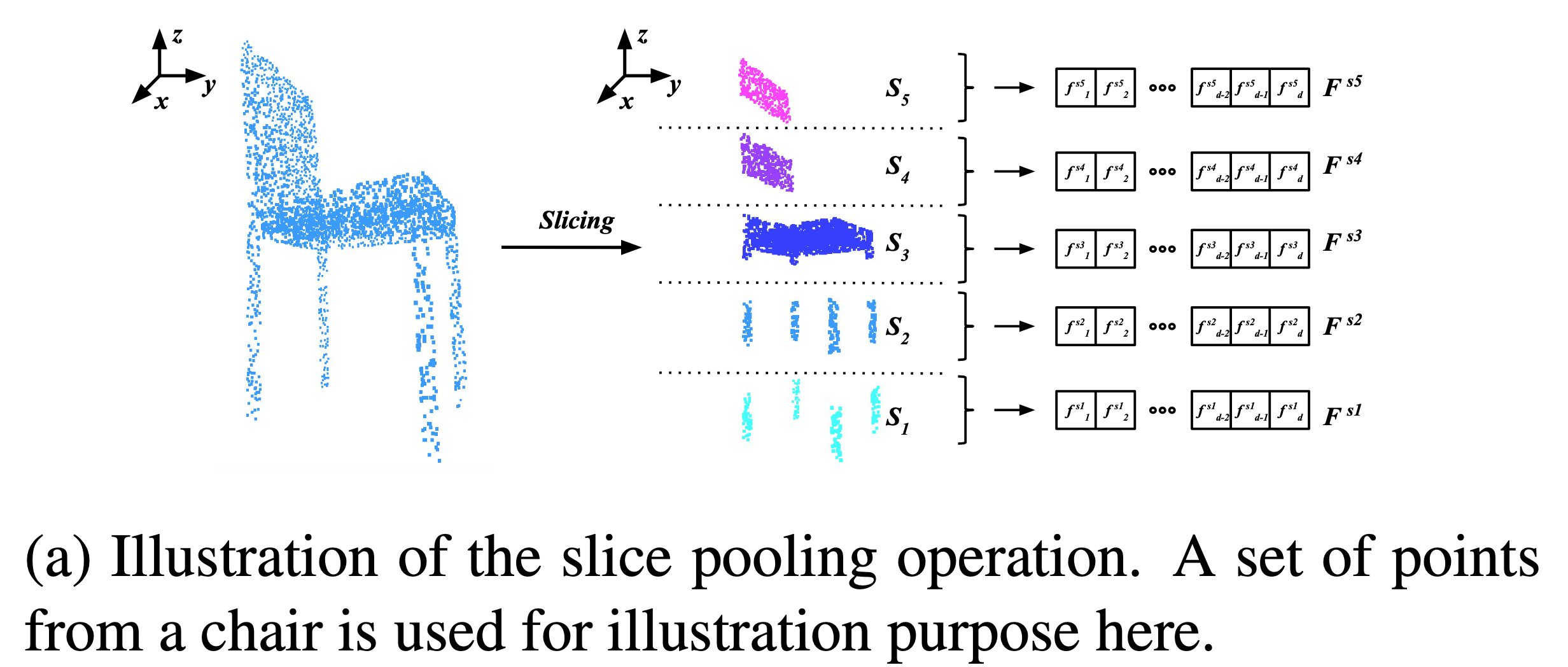
特征的提取是使用pointnet的backbone,并通过maxpool的操作进行pooling😉,可以借鉴一下”funplus”;
4、RNN
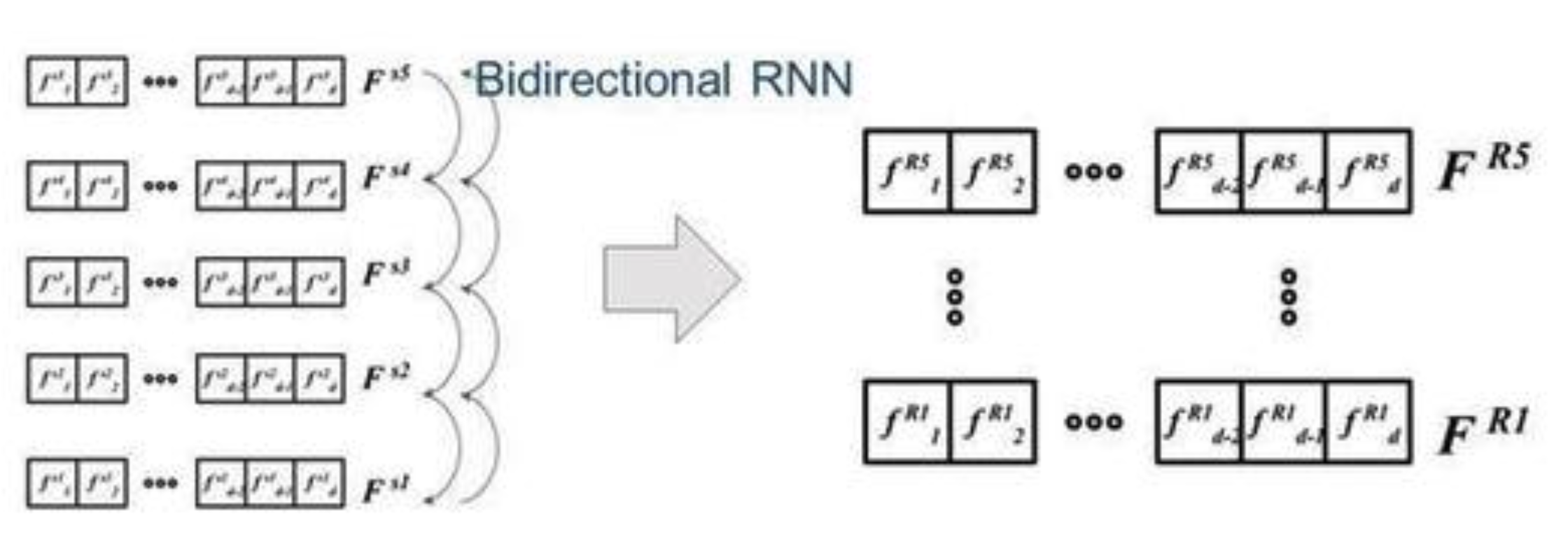
提取feature之后,使用bidirectional RNN去update这个feature,因为相邻的slice有local dependence,所以这样update feature的时候,可以考虑到local的信息,而且因为是bidirectional的,所以不同层的信息也可以相互传递,通过bidirectional传递来的、update过的feature是呈现在这个地方(上图右),在文章中,也对不同的RNN的module做了application study,比如 GRU(这个的表现最好)、STM 等等;
5、slice unpooling operation
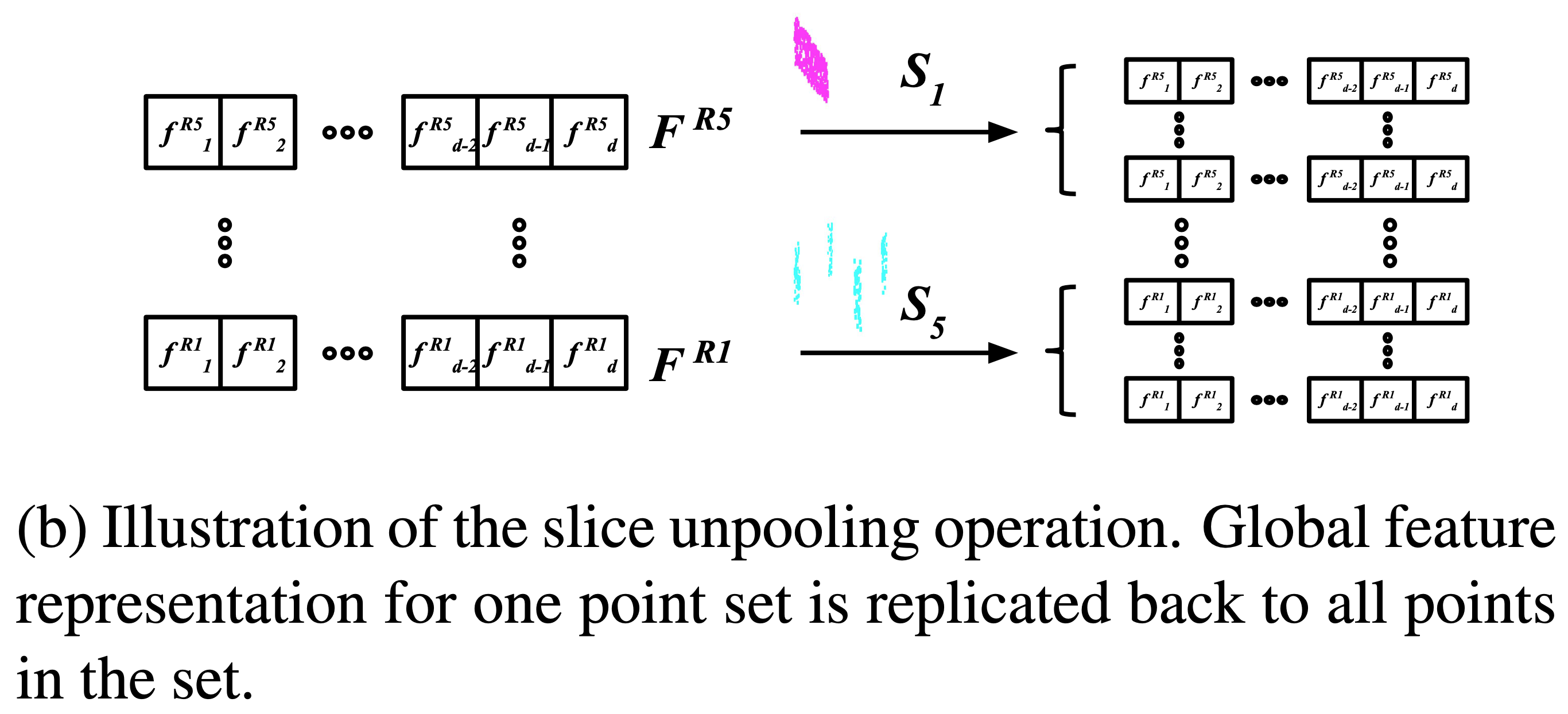
the slice unpooling layer takes updated features Fr as inputs and assigns them back to each point by reversing the projection. This can be easily achieved by storing the slice sets S
unpooling的操作如上英文原文表述,但我有些没有看懂,有时间看看源代码吧!😉
最终的结果在S3DIS上比pointnet好!
SPGraph
这一篇我没看懂,有猛男发了博客点击看猛男,tql!
需要图论的知识,不懂得可以移步新坑点击跳新坑
简单说一说:
网络结构:
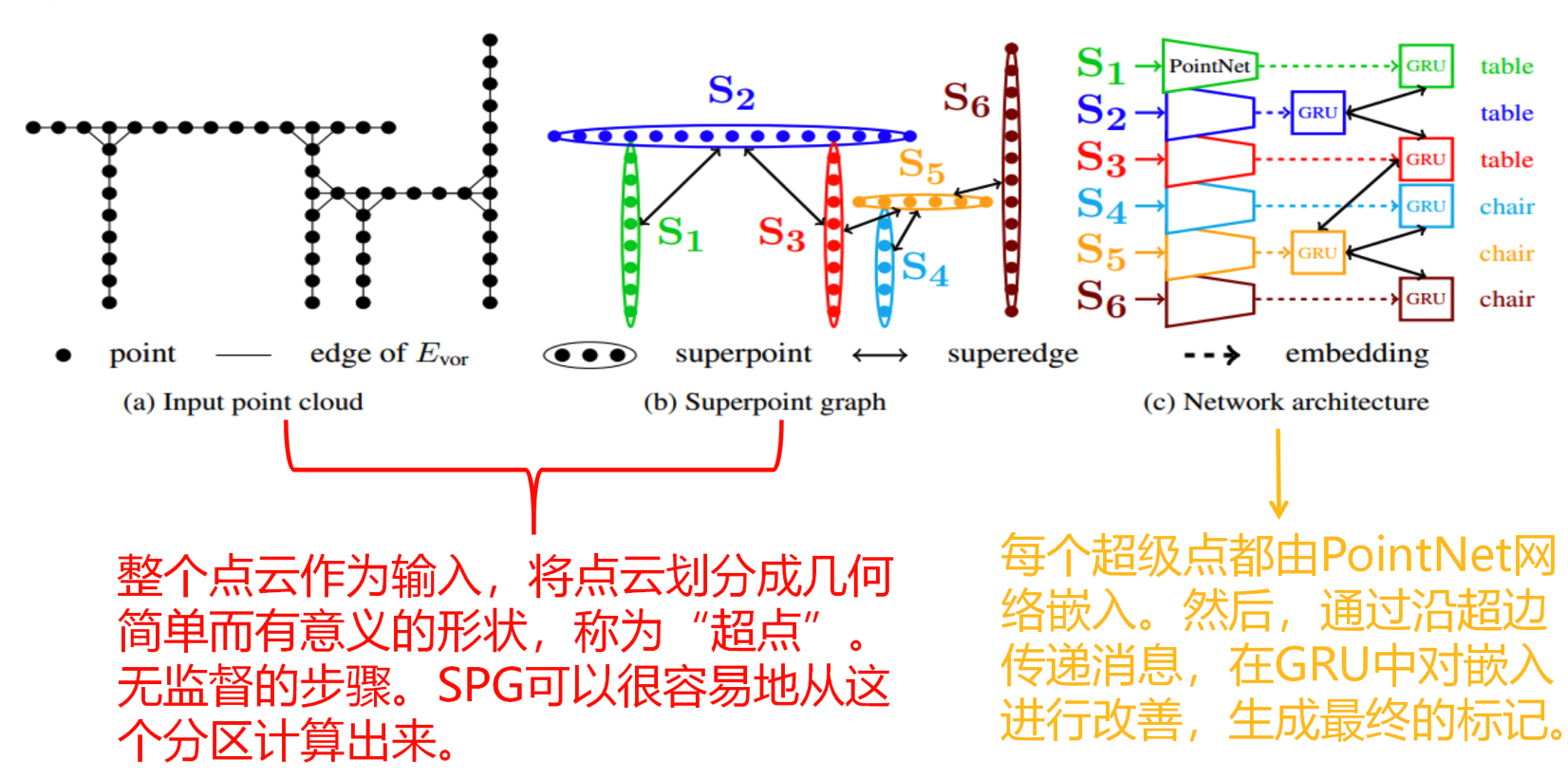
SPG就是“超点”,说是可以通过局部聚类得到这些具有一定几何形状的超点,但我觉得也会有很多偏差;
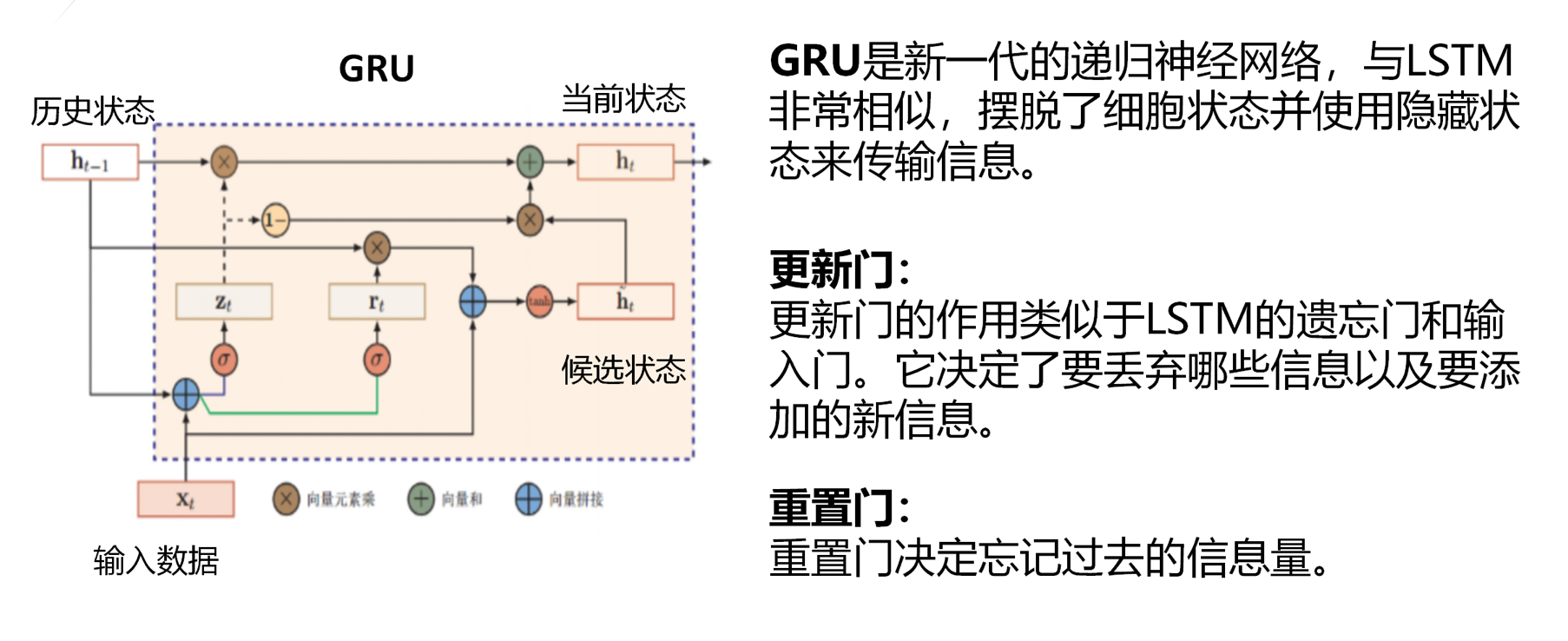
GRU的细节:
在RSnet中也用到了
性能在S3DIS上领先Pointnet(++)
PointCNN
1、基本架构X-Conv:
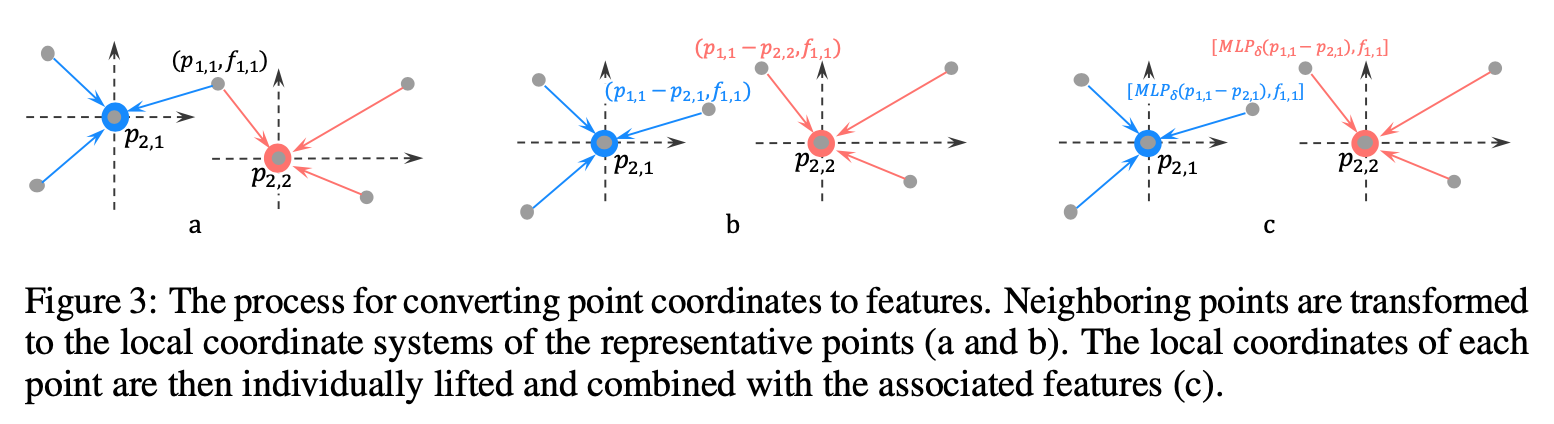

总结:通过MLP产生转化矩阵X,对输入特征进行加权和重新排列,最后再运用典型的卷积 不依赖于排列的前提下能够注意到形状。真得看看图卷积啊啊啊

2、Hierarchical Convolution
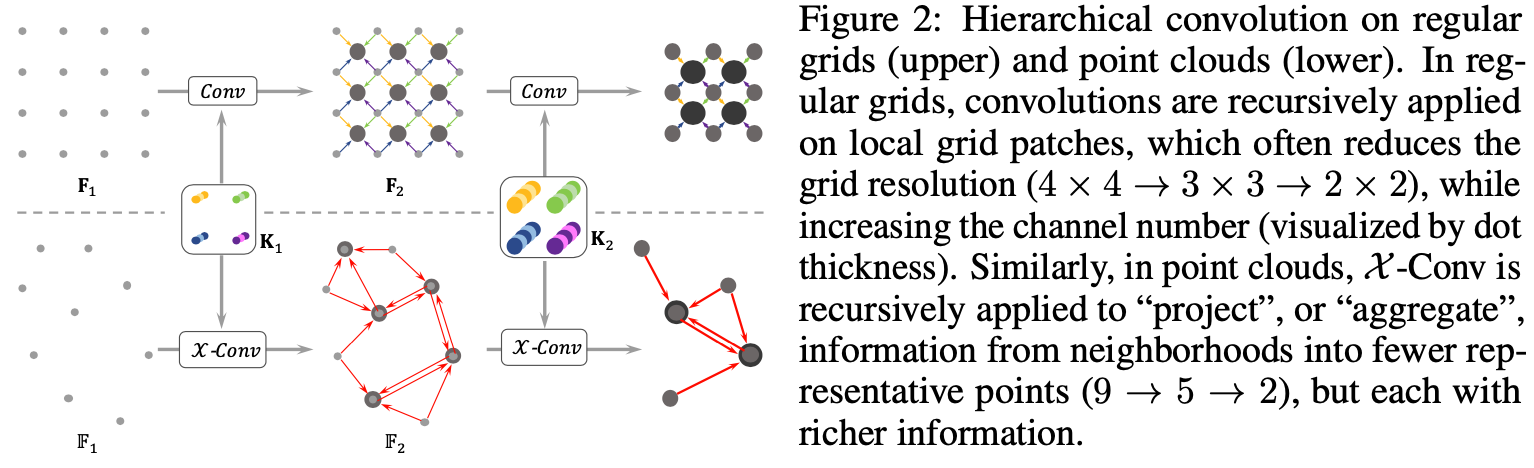
通过x-conv进行pointcloud的卷积操作,representative point的选取:classification是随机down-sampling,而segmentation 是fps(pointnet++)😉
The representative points {p2,i} should be the points that are beneficial for the information “projection” or “aggregation”. In our implementation, they are generated by random down-sampling(随机down sampleing) of {p1,i} in classification tasks, and farthest point sampling(fps) in segmentation tasks, since segmentation tasks are more demanding on a uniform point distribution. We suspect some more advanced point selections which have shown promising performance in geometry processing, such as Deep Points [51], could fit in here as well. We leave the exploration of better representative point generation methods for future work.
3、完整结构
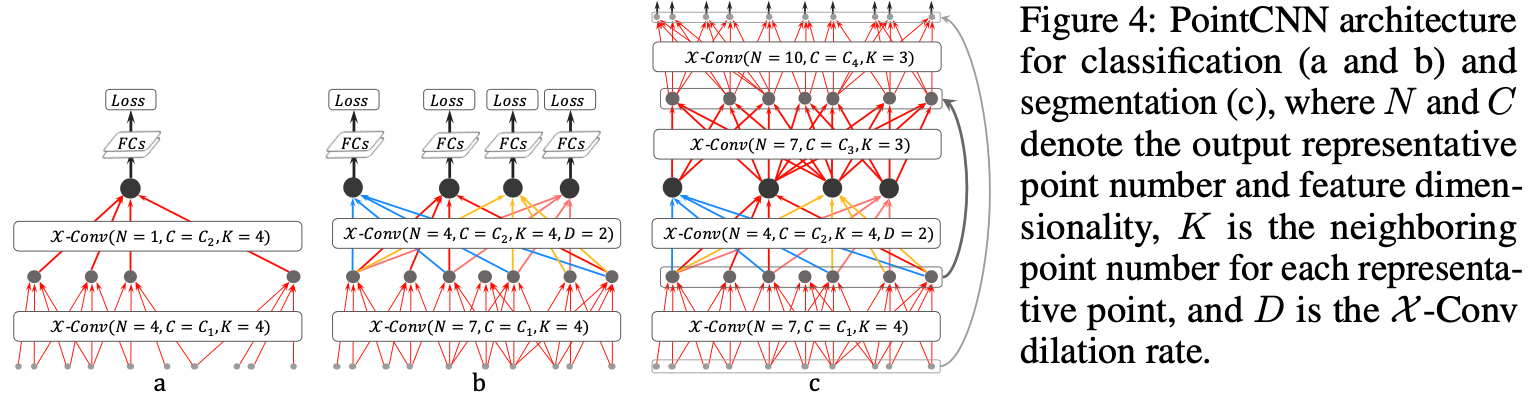
可以看出,在b,c图中借鉴了dilation conv的思想😉;
Dropout is applied before the last fully connected layer to reduce over-fitting.
在S3DIS和ShapeNet上都优于SPGN,SPGraph等前面的论文。
PointSIFT
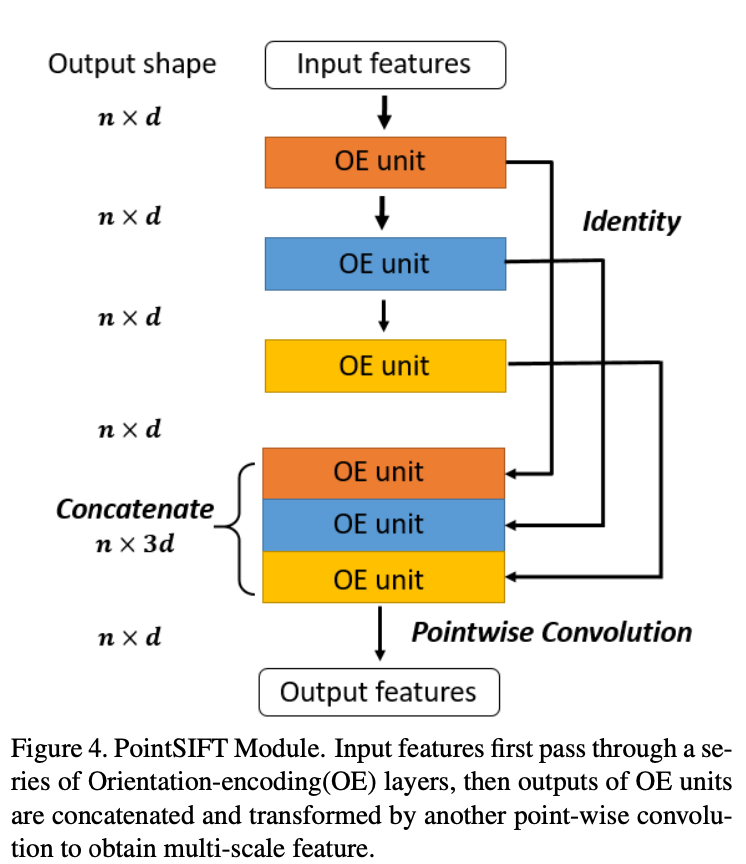
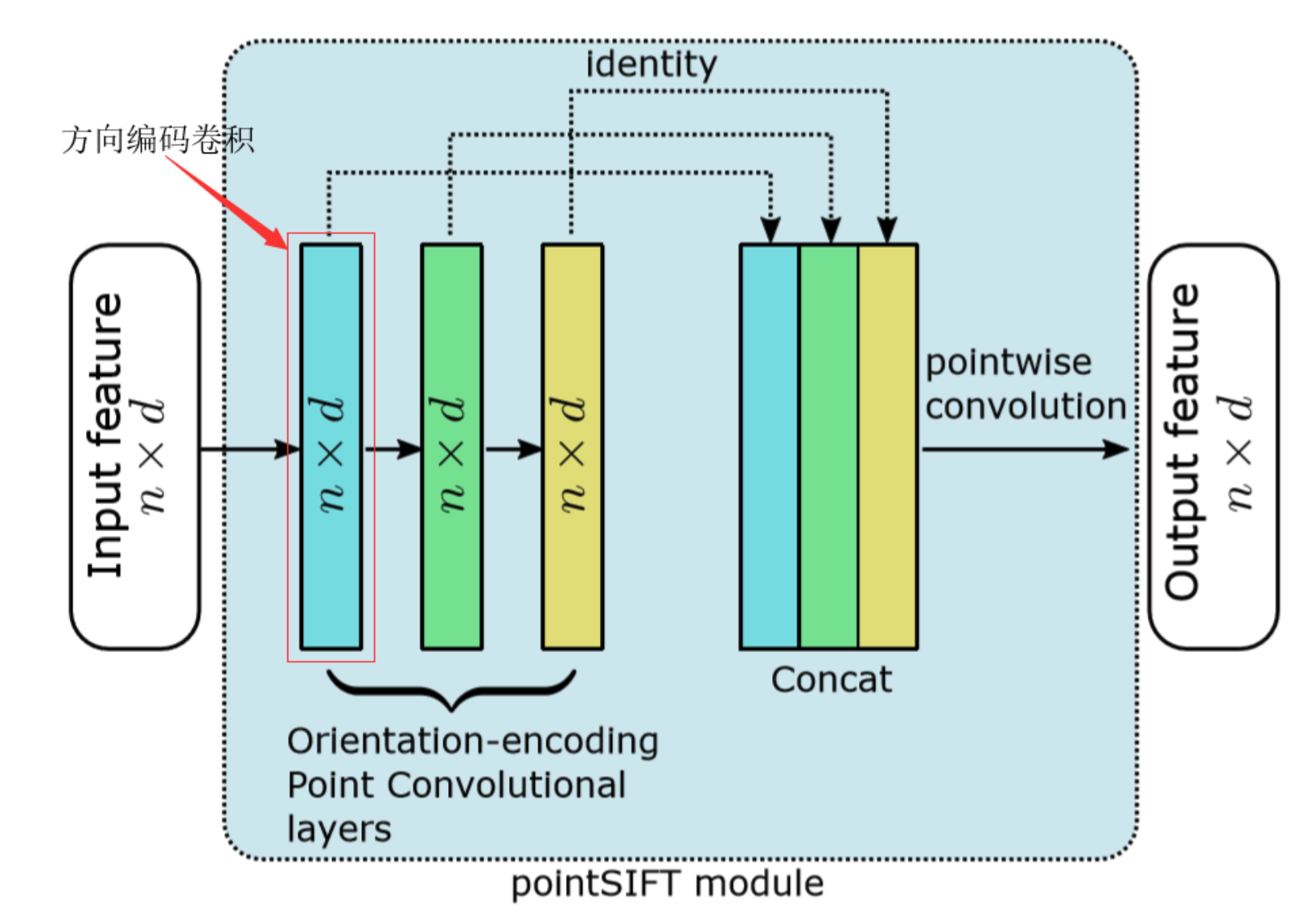
先说PointSIFT module:输入n✖️p,输出也是n✖️p。看上去很简单,内部的更基本的单元是方向编码卷积(OE module)
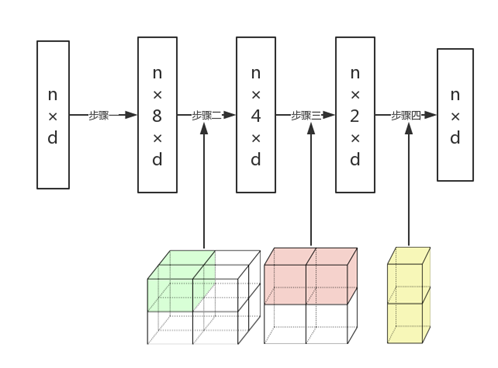

这种类似于将三维点云进行体素化并运用三维卷积的操作,让网络的感受野逐层增加。
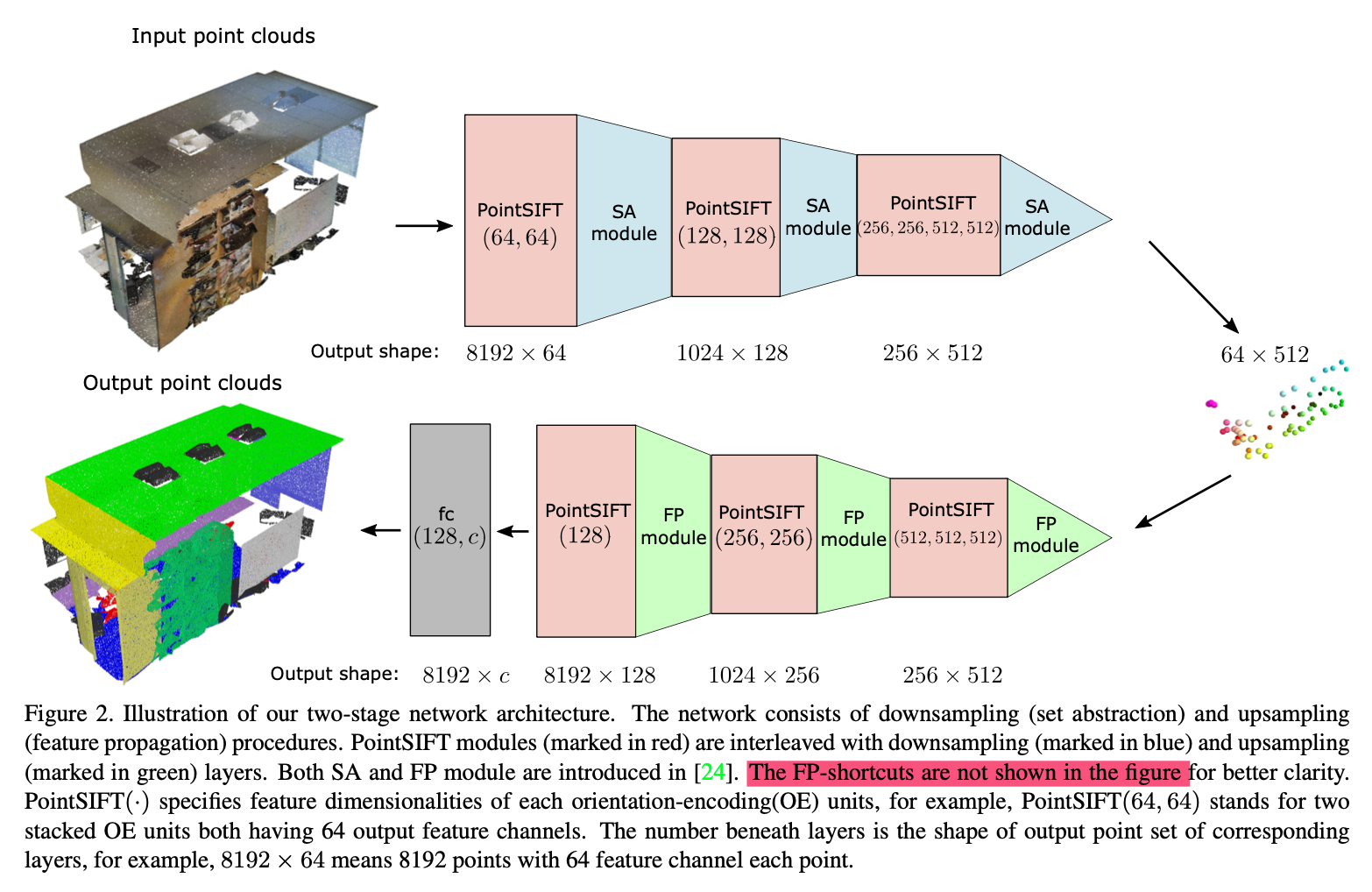
上图是不完整结构(FP module没画出来,还有各种残差连接),其中的SA module是pointnet++中的set abstraction(大家叫它集合抽样层,反正就这么叫吧);FP module是个差值过程,就是简单的欧几里得距离差值(k个近邻点加权求和)😉 详细讲解是click me!
优点在于下采样无信息损耗;8邻域搜索比球搜索好(兼顾了各个方向,不会受到密度干扰😉)
是当时的state of art!在S3DIS上优于Pointnet系列,SPGraph, PointCNN。
ASIS
《Associatively Segmenting Instances and Semantics in Point Clouds》
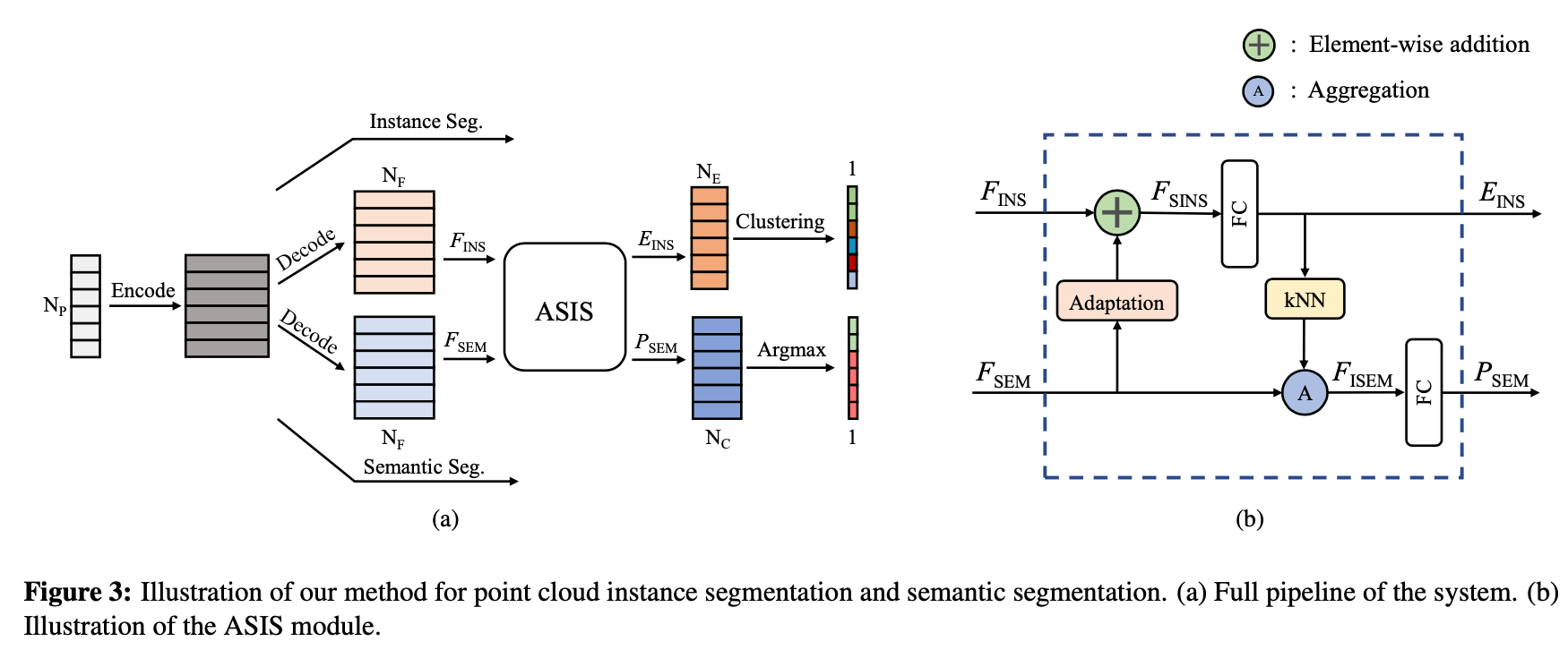
首先介绍了同时分割语义和实例的baseline。方法类似Semantic instance segmentation with a discriminative loss function.中对2D图片的方法,作者将网络修剪成适用于点云的。网络有两个分支:一个是每个点的语义预测;另一个输出点级的嵌套(embeddings), 属于同一个实例的点集靠近,不属于的远离。该baseline在训练和表现上已经比state-of-the-art的SGPN表现好了。基于该基线,提出了ASIS 利用提出的ASIS方法,网络可以学习语义感知的实例嵌套,其中属于不同语义类的点的嵌入通过特征融合进一步自动分离。使得语义分割和实例分割两个任务可以互相借鉴,彼此提高对方的准确度
Np大小的点云首先被提取出来后经过feature encoder(如PointNet层)编码成特征矩阵。这个特征矩阵参考PointNet中局域特征和全局特征结合的矩阵,或者PointNet++最后一个set abstraction的输出。然后两个分支利用特征矩阵分别进行预测。
 其中 I 是真实实例的数目。Ni是实例 i 中点的数目。μi是实例 i 的平均embedding的平均值。l1范数。ej是一个点的embedding。δv and δd are margins; [x]+ = max(0; x) means the hinge.(这部分没有看得太懂,等详细了解了语义分割和实例分割之后,对loss再做分析)
其中 I 是真实实例的数目。Ni是实例 i 中点的数目。μi是实例 i 的平均embedding的平均值。l1范数。ej是一个点的embedding。δv and δd are margins; [x]+ = max(0; x) means the hinge.(这部分没有看得太懂,等详细了解了语义分割和实例分割之后,对loss再做分析)
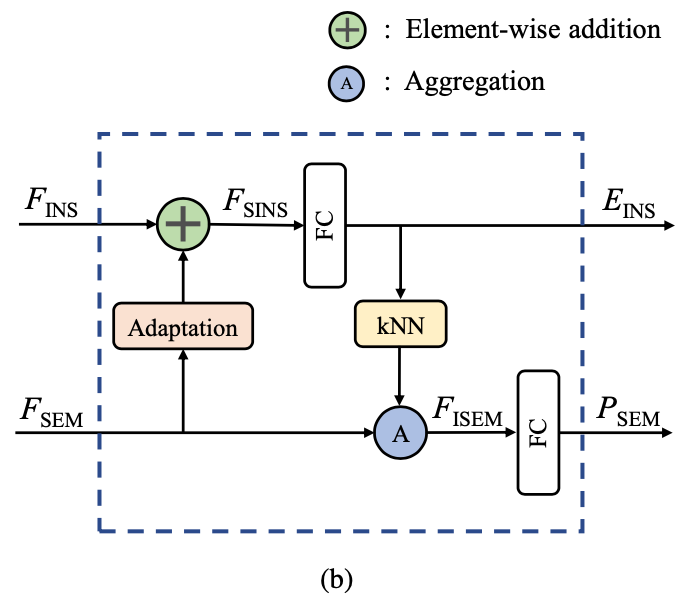
对于ins seg:
FSINS=FINS=+FC(FSEM)
EINS=FC(FSINS)
对于sem seg:
先对EINS进行KNN,为每个点找到K个近邻;根据输出的Np✖️K的矩阵,将FSEM -> Np✖️K✖️NF的矩阵,每组对应于其质心点附近实例嵌入空间中的一个局部区域。 受[26,36,38]三篇论文中channel-wise max aggregation的高效的启发,每一组的语义特征通过channel-wise max aggregation融合到一起,作为图心的精确化的语义特征:即对每个点的K个邻居对应的NF向量取Max,最终将Np✖️K✖️NF的矩阵转为Np✖️NF的矩阵FISEM。再经FC得到ESEM。
基于类别的分析: (1)实例分析中,ASIS模块对周围有其他种类(比如横梁,板, 窗户)的实例帮助比较大。比如板子挂在墙上,板子会容易被忽视,因为板子跟墙形状颜色都很像。语义分割中,ASIS对有复杂形状的物体帮助较大。 (2)不足:两个靠近的椅子被认为是同一个实体。“We leave it to future works to explore better solutions.”(加油少年!)